Understanding YOLOv8 Architecture: A Breakthrough in Real-time Artifact Detection
Dr. Ameera Al-Karkhi
Sheridan College/ Faculty of Applied Science and Technology
Identifying and locating objects in images or videos, and their positioning is made possible with computer vision. A variety of techniques and algorithms have been developed over time, and Convolutional Neural Networks offers the greatest performance for completing such tasks, among all.
On completed industrial objects, visual faults like scratches and cracks are frequently seen, which poses a hazard to the quality of the production process. An essential task in the manufacturing process is the reliable and precise automatic identification of such visual defects.
The advanced object identification algorithm known as You Only Look Once version 8 (YOLOv8) has attracted a lot of interest, due to its real-time characteristics and great accuracy. We explain YOLOv8’s architecture, examining its distinctive features and the way it transforms object detection.
The main perception of YOLO is to instantly perform detection on the full image in only one pass, in contrast to time-consuming region proposal techniques. Since its conception, YOLO has gone through a few iterations, each of which has improved upon the one before it. The most recent development, YOLOv8, provides improved accuracy and speed.
The YOLOv8 architecture’s feature extraction backbone analyses the input image and extracts hierarchical features first. It frequently uses Darknet-53, a deep convolutional neural network with 53 layers, as the kernel of the object detection technique to capture meaningful representations at various dimensions. As a result, YOLOv8 can identify objects of various sizes and aspect ratios with accuracy.
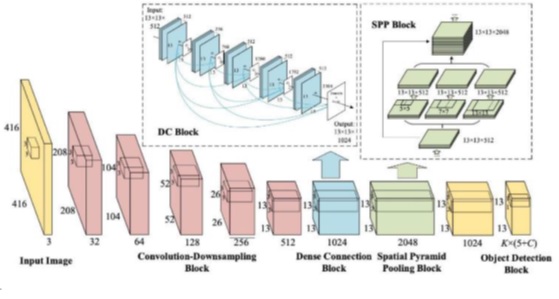
One of YOLOv8’s key advantages is the merging of multi-scale features. The architecture combines characteristics from numerous layers with various spatial resolutions to produce a comprehensive representation that may capture both local and global context. This fusion is performed by a series of concatenations and upsampling processes, enabling YOLOv8 to maintain fine-grained properties while preserving the broader context.
YOLOv8 predicts bounding boxes and class probabilities at different scales. The incorporation of anchors, which are established bounding box priors, simplifies the prediction process. By employing anchors with different sizes and aspect ratios, YOLOv8 can recognise objects with a range of features. Each anchor has a set of class probabilities that indicate the possibility that certain object classes will appear inside the anchor’s predicted bounding box.
Non-maximum suppression (NMS), a technique, is used by YOLOv8 to eliminate unnecessary detections. After predicting many bounding boxes for each grid cell, the NMS eliminates overlapping boxes with lower confidence ratings, keeping only the most certain detection. At this point of the process, making sure that each object is represented by a single bounding box increases the output’s accuracy.
YOLOv8 represents a significant shift in the object detection industry with its robust and efficient response for real-time applications. Its design combines a feature extraction backbone with multi-scale feature fusion, predictions at various sizes, and precise and quick object detection. The precision and dependability of YOLOv8’s output are increased with the aid of anchor boxes and non-maximum suppression. As technology advances, we might expect greater advancements in object detection algorithms, with YOLOv8 creating the foundation for even harder issues to arise in the future.
Reference:
*Shodiq, Moh & Penangsang, Yoga. (2023). Detecting Potholes Using Deep Learning. Journal of Computer Engineering, Network, and Intelligent Multimedia. 1. 44-49. 10.59378/jcenim.v1i1.7.